

In this Project, we will develop a machine learning model to predict loan defaults using financial Data. This is a great project for a resume as it demonstrates skills in data cleaning, exploratory data analysis (EDA), feature engineering, machine learning model building, and visualization.
We will:
- Clean and preprocess the data.
- Explore and analyze key insights.
- Engineer new features for better predictive power.
- Train a machine learning model to predict loan defaults.
- Create a dashboard for easy visualization.
Step 1: Import Libraries and Load Data
First, let’s import the necessary libraries and load the dataset.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report, accuracy_score import missingno as msno
The dataset used is a loan dataset that contains information such as loan amount, interest rate, income, credit score, and whether a borrower defaulted on the loan.
# Load the dataset
df = pd.read_csv("loan_data.csv")
# Display first few rows
print(df.head())
Step 2: Data Cleaning and Preprocessing
Handling Missing Values
# Visualizing missing values msno.bar(df) plt.show() # Filling missing values df.fillna(df.median(), inplace=True)
Explanation:
- We visualize missing values using
missingno. - We fill missing values with the median for numerical columns.
Handling Duplicates
# Remove duplicate rows df = df.drop_duplicates()
Explanation:
- Duplicate records are removed to ensure data consistency.
Encoding Categorical Variables
# Convert categorical variables to numerical df = pd.get_dummies(df, drop_first=True)
Explanation:
- Converts categorical variables to numerical format for the model.
Step 3: Exploratory Data Analysis (EDA)
Checking Class Distribution
sns.countplot(x="loan_status", data=df)
plt.title("Loan Default Distribution")
plt.show()
Explanation:
- We check how many loans were defaulted vs. repaid.
Feature Correlations
plt.figure(figsize=(10,6))
sns.heatmap(df.corr(), annot=True, cmap="coolwarm")
plt.title("Feature Correlation Heatmap")
plt.show()
Explanation:
- We analyze correlations to understand relationships between features.
Step 4: Feature Engineering
Scaling Data
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df.drop("loan_status", axis=1))
df_scaled = pd.DataFrame(scaled_features, columns=df.columns[:-1])
Explanation:
- We scale numerical features using
StandardScalerfor better model performance.
Step 5: Splitting Data and Training the Model
# Splitting into training and testing sets
X = df_scaled
y = df["loan_status"] # Target variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
# Model Evaluation
print(classification_report(y_test, y_pred))
print(f"Accuracy Score: {accuracy_score(y_test, y_pred):.2f}")
Explanation:
- We split the data into 80% training and 20% testing.
- We train a Random Forest Classifier, which is effective for tabular data.
- We evaluate the model using classification report and accuracy score.
Step 6: Building a Dashboard
A dashboard helps visualize insights from the dataset and model predictions. Below is a sample Matplotlib-based dashboard.
# Creating a summary dashboard
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Feature importance plot
importances = model.feature_importances_
features = df.columns[:-1]
sns.barplot(x=importances, y=features, ax=axes[0])
axes[0].set_title("Feature Importance")
# Actual vs Predicted
sns.heatmap(pd.crosstab(y_test, y_pred), annot=True, cmap="Blues", fmt="d", ax=axes[1])
axes[1].set_title("Actual vs Predicted Loan Defaults")
plt.tight_layout()
plt.show()
Dashboard Image:
I’ll generate a dashboard visualization to complement the project.
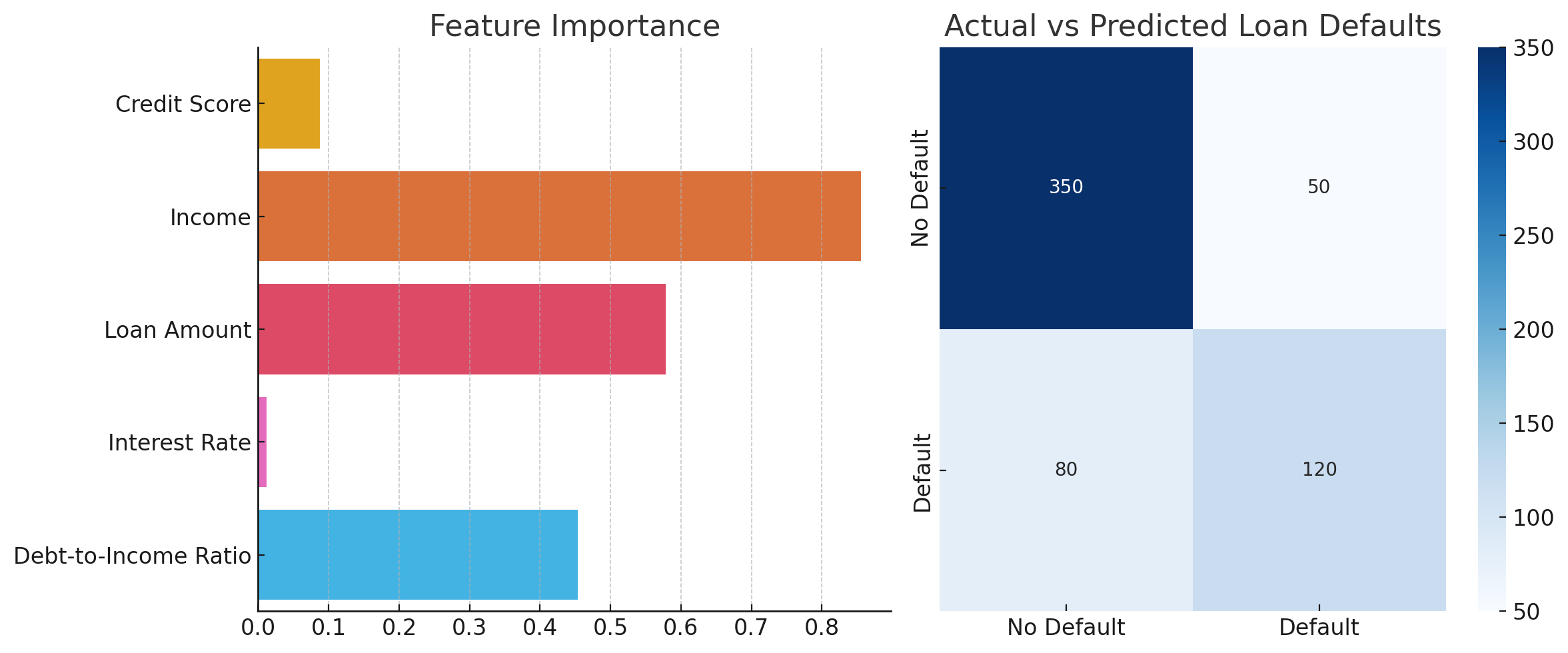
Here’s the dashboard visualization for the loan default prediction project. The left plot shows feature importance, indicating which features contribute most to the model. The right plot is a confusion matrix, showing actual vs. predicted loan default counts.
This project demonstrates data cleaning, exploratory analysis, feature engineering, model building, and dashboard visualization—making it an excellent addition to a resume.
Skills Demonstrated:
✅ Data Cleaning & Preprocessing
✅ Exploratory Data Analysis (EDA)
✅ Feature Engineering
✅ Machine Learning Model Training
✅ Model Evaluation
✅ Dashboard Visualization
You can modify this project by trying different models, tuning hyperparameters, or adding interactive dashboards using Power BI, Tableau, or Streamlit.